Speech Synthesis
The demand for sophisticated text-to-speech technology has grown in tandem with increasing reliance on personal assistant type programs for simple daily tasks and navigation. This comes in the form of navigation software such as Google Maps as well as personal assistant programs like Amazon's Alexa, Apple's Siri or Microsoft's Cortana. All of these programs are incredibly well developed and polished voices that while not entirely sounding human, rarely make any discernable errors in fluency. Less widely distributed speech synthesis programs, which are most often used for accessibility such as screen-readers, are typically not as polished or refined as the flagship personal assistants. It is important to recognize why this is, and what is actually happening under the hood.
Concatenation
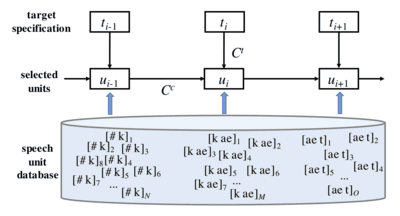
The secret to the fluency of the major text-to-speech programs is that they are not really true speech synthesis. The most successful method for producing fluent and mostly natural sounding speech has been a method called concatenation. In reality, all the speech that Siri speaks to you comes from spliced apart and rearranged speech samples from an actual human named Susan Bennet. Presumably, the concatenated speech is cleaned up by some kind of algorithm before it reaches the user, but ultimately the content of the speech sounds are sourced from non-synthetic voices. There are several different ways to splice and rearrange a corpus of speech samples to mimic natural human speech, each with their own advantages and disadvantages.
Phone-by-Phone Concatenation
Every indivisible speech sound, or phone, can be isolated from a speech sample and run one after another to recreate human speech sounds. This method is the easiest for anybody putting together a speech synthesis program. However, this method results in crude, disjointed speech that can become non-fluent, and almost certainly will not sound like natural human speech.
Diphone Concatenation
Between two consecutive phones in a word, there are suprasegmental variations in the pronunciation at the end of one sound and the beginning of the next. This variation is one of the primary reasons that single phone concatenation runs into fluency problems. The library of available concatenating units can instead consist of segments that match the end of one phone with the beginning of another (/ta/ for example) while excluding the first half of the first phone, and the last half of the second phone. The necessary library of sounds needed to utilize this method is significantly larger than single phone concatenation as it must contain a combination of most of a language's phones, as well as all cases where a pair of phones are combined twice in two different orders. An advantage of this is that these sound combinations are easy to pull out of a sample of spoken language, despite the amount of segments needed.
Syllable Concatenation
As syllables typically fit together as a distinct and internally fluent division of speech, as well as a building block of human speech, syllable concatenation is also considered a candidate for speech synthesis. Syllables theoretically can provide a very high level of intelligibility, however there are challenges in this approach. While this approach makes a lot of sense for Japanese, which has about 100 possible syllables, this approach would require a tremendous amount of word to set up and resources to reference a language like English, which has an excess of 100,000 possible syllables.
Morpheme and Word Concatenation
A morpheme is an indivisible unit of semantic meaning. It is the smallest unit that one can break a word into that still carries meaning. Morphemes and words, like syllables, can be concatenated, but a database of usable samples would become very large and complicated if morphemes and words are included. However, this method could potentially improve fluency issues, though the lack of concern for the suprasegmental space between the end of one word and the beginning of another could also mean that this method can lead to significant fluency problems.
Phrases, Sentences, and Combinations
While the amount of possible phrases and sentences in a language is functionally infinite and therefore impossible to store in a database, it is important to consider their role in speech concatenation, as it mimics how humans actually use language. We do not systematically reconstruct every phrase and sentence we use on a daily or weekly basis out of its constituent words. We have a library of canned phrases and sentences that we reference every day (e.g. "how's it going?", "what's for dinner?", "if this, then that"). It may make sense to have a collection of phrases or sentences that are incredibly common in speech left intact for this reason, as it can make synthetic speech sound more natural simply because these phrases occur so often. This segues into the reality that ultimately, it is almost certain that the most widely-used speech synthesis programs utilize a combination of these segment types.